spark on k8s operator
spark on k8s operator
Spark operator是一个管理Kubernetes上的Apache Spark应用程序生命周期的operator,旨在像在Kubernetes上运行其他工作负载一样简单的指定和运行spark应用程序。
使用Spark Operator管理Spark应用,能更好的利用Kubernetes原生能力控制和管理Spark应用的生命周期,包括应用状态监控、日志获取、应用运行控制等,弥补Spark on Kubernetes方案在集成Kubernetes上与其他类型的负载之间存在的差距。
Spark Operator包括如下几个组件:
- SparkApplication控制器:该控制器用于创建、更新、删除SparkApplication对象,同时控制器还会监控相应的事件,执行相应的动作。
- Submission Runner:负责调用spark-submit提交Spark作业,作业提交的流程完全复用Spark on K8s的模式。
- Spark Pod Monitor:监控Spark作业相关Pod的状态,并同步到控制器中。
- Mutating Admission Webhook:可选模块,基于注解来实现Driver/Executor Pod的一些定制化需求。
- SparkCtl:用于和Spark Operator交互的命令行工具。
安装
# 添加源
helm repo add spark-operator https://googlecloudplatform.github.io/spark-on-k8s-operator
# 安装
helm install my-release spark-operator/spark-operator --namespace spark-operator --create-namespace这个时候如果直接执行kubectl apply -f examples/spark-pi.yaml调用样例,会出现以下报错,需要创建对象的serviceaccount。
forbidden: error looking up service account default/spark: serviceaccount \"spark\" not found.\n\tat io.fabric8.kubernetes.client.dsl.base.OperationSupport.requestFailure(OperationSupport.java:568)\n\tat io.fabric8.kubernetes.client.dsl.base.OperationSupport同时也要安装rbac
rbac的文件在manifest/spark-operator-install/spark-operator-rbac.yaml,需要把namespace全部改为需要运行的namespace,这里我们任务放在default命名空间下,所以全部改为default,源文件见rbac.yaml
执行脚本,这里用的app.jar是一个读取es数据源,然后计算,为了展示效果,在程序的后面用了TimeUnit.HOURS.sleep(1)方便观察。
代码如下:
SparkConf sparkConf = new SparkConf().setAppName("Spark WordCount Application (java)");
sparkConf.set("es.nodes", "xxx")
.set("es.port", "8xx0")
.set("es.nodes.wan.only", "true")
.set("es.net.http.auth.user", "xxx")
.set("es.net.http.auth.pass", "xxx-xxx");
try (JavaSparkContext jsc = new JavaSparkContext(sparkConf)) {
JavaRDD<Map<String, Object>> esRDD = JavaEsSpark.esRDD(jsc, "kibana_sample_data_ecommerce").values();
System.out.println(esRDD.partitions().size());
esRDD.map(x -> x.get("customer_full_name"))
.countByValue()
.forEach((x, y) -> System.out.println(x + ":" + y));
TimeUnit.HOURS.sleep(1);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}打包之后kubectl create -f k8s.yaml即可
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:
name: spark-demo
namespace: default
spec:
type: Scala
mode: cluster
image: fewfew-docker.pkg.coding.net/spark-java-demo/spark-java-demo-new/spark-java-demo:master-1d8c164bced70a1c66837ea5c0180c61dfb48ac3
imagePullPolicy: Always
mainClass: com.spark.es.demo.EsReadGroupByName
mainApplicationFile: "local:///opt/spark/examples/jars/app.jar"
sparkVersion: "3.1.1"
restartPolicy:
type: Never
driver:
# 用cores必须要大于等于1,这里用coreRequest
coreRequest: "100m"
coreLimit: "1200m"
memory: "512m"
labels:
version: 3.1.1
serviceAccount: sparkoperator
executor:
# 用cores必须要大于等于1,这里用coreRequest
coreRequest: "100m"
instances: 1
memory: "512m"
labels:
version: 3.1.1spark-demo-driver 1/1 Running 0 2m30s
spark-wordcount-application-java-0ac352810a9728e1-exec-1 1/1 Running 0 2m1s同时会自动生成相应的service。

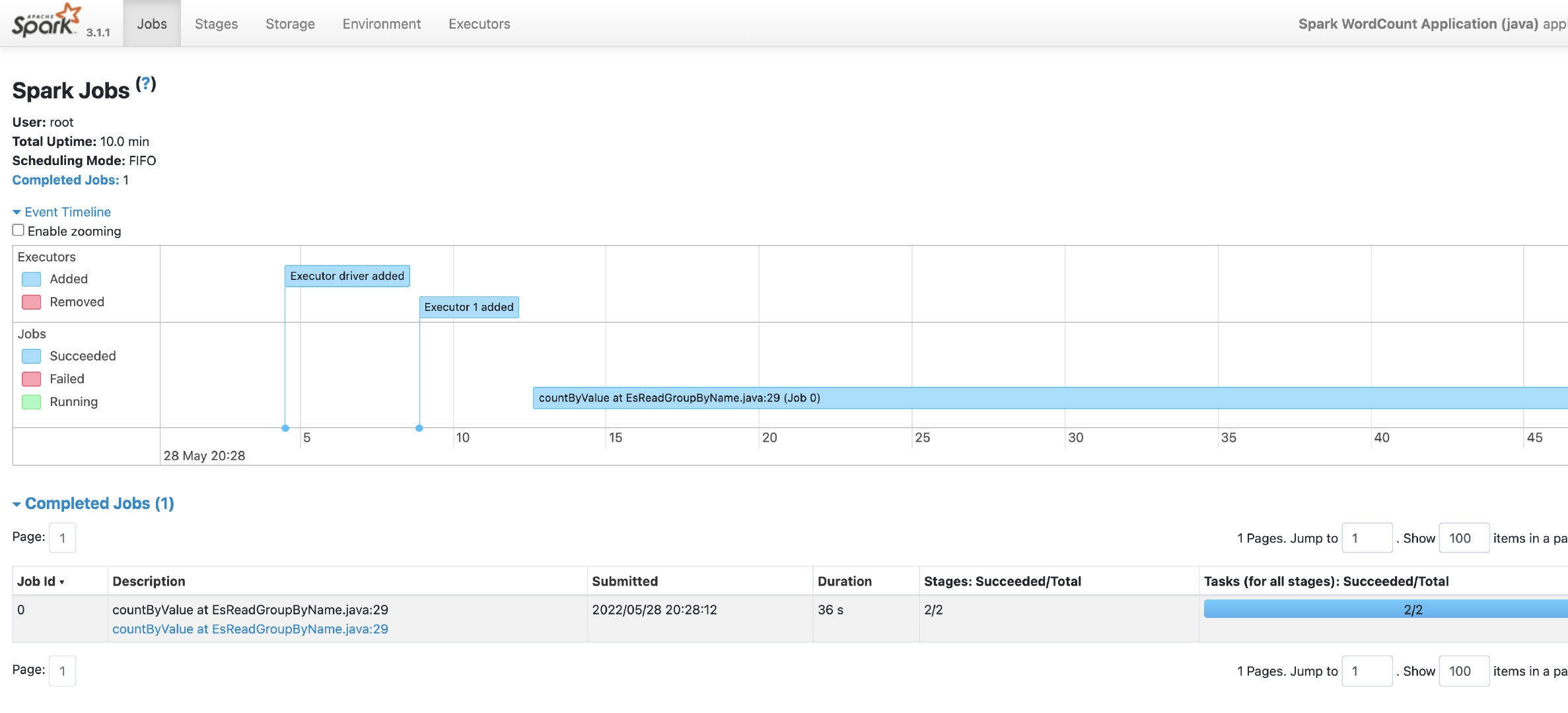
Spark on k8s operator大大减少了spark的部署与运维成本,用容器的调度来替换掉yarn,
源码解析
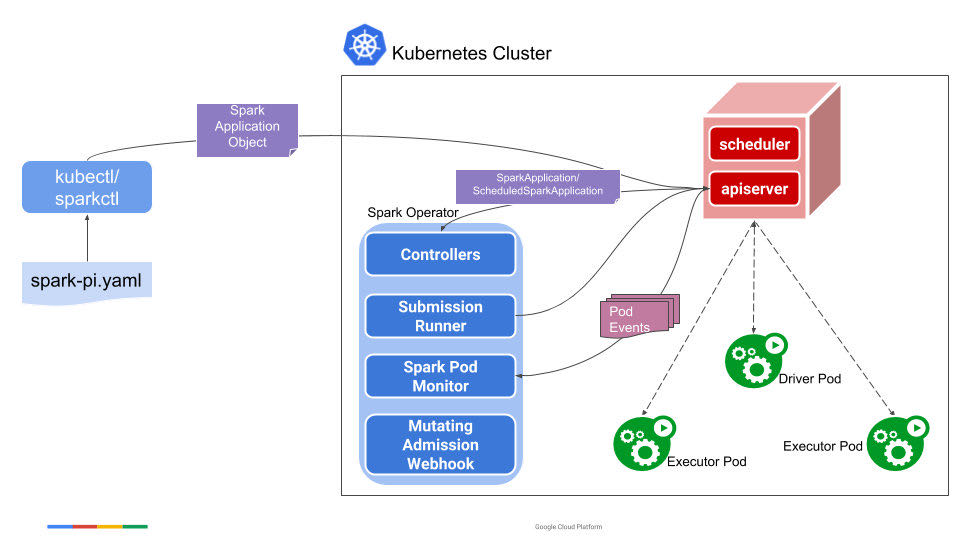
Spark Operator的主要组件如下:
1、SparkApplication Controller : 用于监控并相应SparkApplication的相关对象的创建、更新和删除事件;
2、Submission Runner:用于接收Controller的提交指令,并通过spark-submit 来提交Spark作业到K8S集群并创建Driver Pod,driver正常运行之后将启动Executor Pod;
3、Spark Pod Monitor:实时监控Spark作业相关Pod(Driver、Executor)的运行状态,并将这些状态信息同步到Controller ;
4、Mutating Admission Webhook:可选模块,但是在Spark Operator中基本上所有的有关Spark pod在Kubernetes上的定制化功能都需要使用到该模块,因此建议将enableWebhook这个选项设置为true。
5、sparkctl: 基于Spark Operator的情况下可以不再使用kubectl来管理Spark作业了,而是采用Spark Operator专用的作业管理工具sparkctl,该工具功能较kubectl功能更为强大、方便易用。
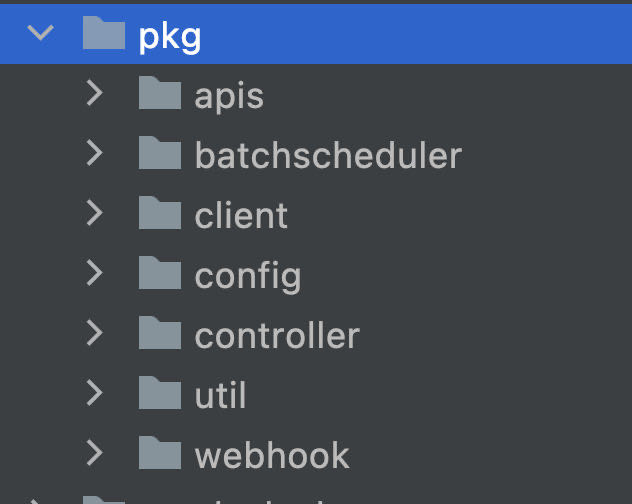
apis:用户编写yaml时的解析
Batchscheduler:批处理的调度,提供了支持volcano的接口
Client:
leader的选举
electionCfg := leaderelection.LeaderElectionConfig{
Lock: resourceLock,
LeaseDuration: *leaderElectionLeaseDuration,
RenewDeadline: *leaderElectionRenewDeadline,
RetryPeriod: *leaderElectionRetryPeriod,
Callbacks: leaderelection.LeaderCallbacks{
OnStartedLeading: func(c context.Context) {
close(startCh)
},
OnStoppedLeading: func() {
close(stopCh)
},
},
}
elector, err := leaderelection.NewLeaderElector(electionCfg)参考: