4.日志系统.md
4.日志系统.md
欢迎访问我的网站http://www.wenzhihuai.com/ 。感谢,如果可以,希望能在GitHub上给个star,GitHub地址https://github.com/Zephery/newblog 。
建立网站少不了日志系统,用来查看网站的访问次数、停留时间、抓取量、目录抓取统计、页面抓取统计等,其中,最常用的方法还是使用ELK,但是,本网站的服务器配置实在太低了(1GHZ、2G内存),压根就跑不起ELK,所以只能寻求其他方式,目前最常用的有百度统计和友盟,这里,本人使用的是百度统计,提供了API给开发者使用,能够将自己所需要的图表移植到自己的网站上。日志是网站及其重要的文件,通过对日志进行统计、分析、综合,就能有效地掌握网站运行状况,发现和排除错误原因,了解客户访问分布等,更好的加强系统的维护和管理。下面是我的百度统计的概览页面:
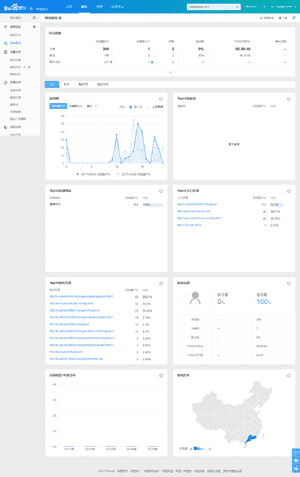
企业级的网站日志不能公开,但是我的是个人网站,用来跟大家一起学习的,所以,需要将百度的统计页面展示出来,但是,百度并不提供日志的图像,只提供API给开发者调用,而且还限制访问次数,一天不能超过2000次,这个对于实时统计来说,确实不够,所以只能展示前几天的访问统计。这里的日志系统分为三个步骤:1.API获取数据;2.存储数据;3.展示数据。页面效果如下,也可以点开我的网站的日志系统:
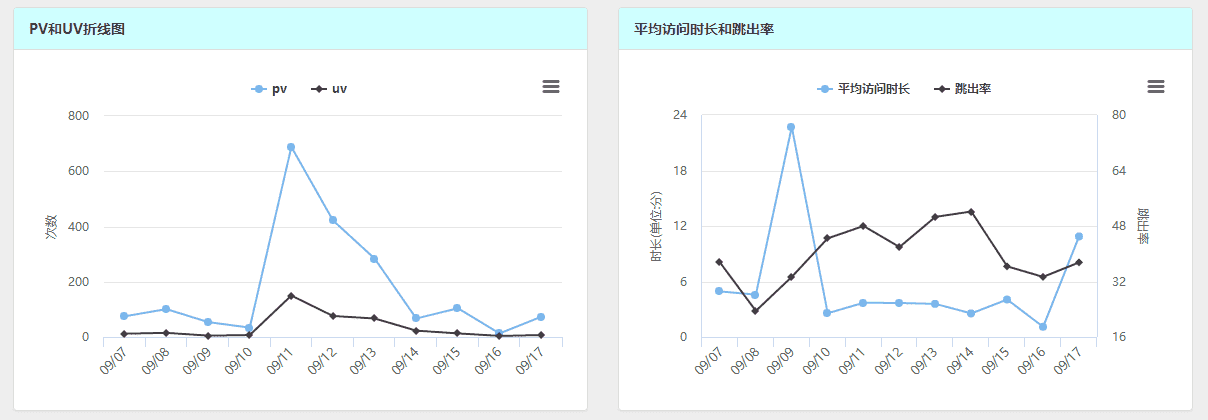

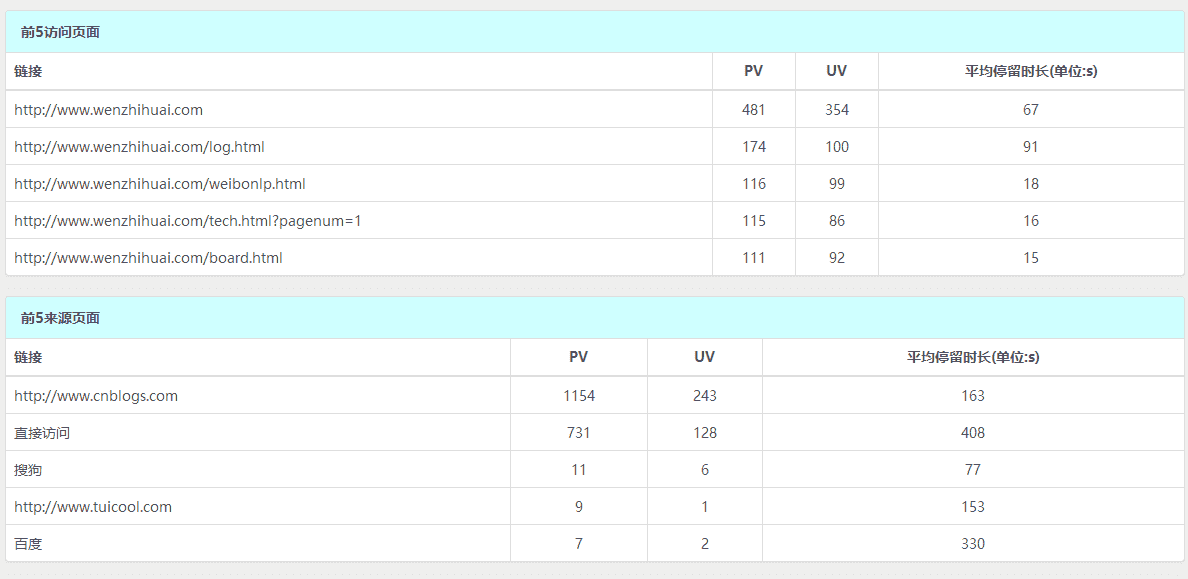
百度统计提供了Tongji API的Java和Python版本,这两个版本及其复杂,可用性极低,所以,本人用Python写了个及其简单的通用版本,整体只有28行,代码在这,https://github.com/Zephery/baidutongji。下面是具体过程
1.网站代码安装
先在百度统计中注册登录之后,进入管理页面,新增网站,然后在代码管理中获取安装代码,大部分人的代码都是类似的,除了hm.js?后面的参数,是记录该网站的唯一标识。
<script>
var _hmt = _hmt || [];
(function() {
var hm = document.createElement("script");
hm.src = "https://hm.baidu.com/hm.js?code";
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(hm, s);
})();
</script>同时,需要在申请其他设置->数据导出服务中开通数据导出服务,百度统计Tongji API可以为网站接入者提供便捷的获取网站流量数据的通道。
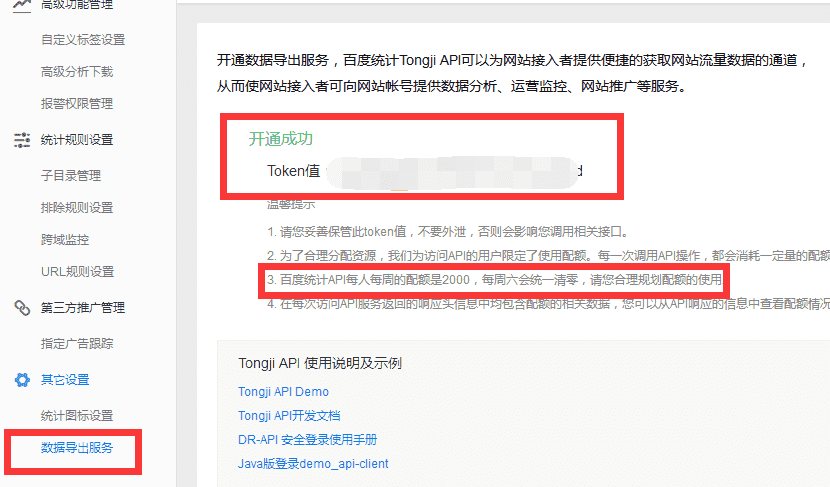
至此,我们获得了username、password、token,然后开始使用三个参数来获取数据。
2.根据API获取数据
官网的API详细的记录了接口的参数以及解释, 链接:https://api.baidu.com/json/tongji/v1/ReportService/getData,详细的官方报告请访问官网TongjiApi 所需参数(必须):
| 参数名称 | 参数类型 | 描述 |
|---|---|---|
| method | string | 要查询的报告 |
| start_date | string | 查询起始时间 |
| end_date | string | 查询结束时间 |
| metrics | string | 自定义指标 |
其中,参数start_date和end_date的规定为:yyyyMMdd,这里我们使用python的原生库,datetime、time,获取昨天的时间以及前七天的日期。
today = datetime.date.today() # 获取今天的日期
yesterday = today - datetime.timedelta(days=1) # 获取昨天的日期
fifteenago = today - datetime.timedelta(days=7) # 获取前七天的日期
end, start = str(yesterday).replace("-", ""), str(fifteenago).replace("-", "") # 格式化成yyyyMMdd格式3.构建请求
说明:siteId可以根据个人百度统计的链接获取,也可以使用Tongji API的第一个接口列表获取用户的站点列表。首先,我们构建一个类,由于username、password、token都是通用的,所以我们将它设置为构造方法的参数。
class Baidu(object):
def __init__(self, siteId, username, password, token):
self.siteId = siteId
self.username = username
self.password = password
self.token = token然后构建一个共同的方法,用来获取提交数据之后返回的结果,其中提供了4个可变参数,分别是(start_date:起始日期,end_date:结束日期,method:方法,metrics:指标),返回的是字节,最后需要decode("utf-8")一下变成字符:
def getresult(self, start_date, end_date, method, metrics):
body = {"header": {"account_type": 1, "password": self.password, "token": self.token,
"username": self.username},
"body": {"siteId": self.siteId, "method": method, "start_date": start_date,
"end_date": end_date,
"metrics": metrics}}
data = bytes(json.dumps(body), 'utf8')
req = urllib.request.Request(base_url, data)
response = urllib.request.urlopen(req)
the_page = response.read()
return the_page.decode("utf-8")至此,python获取百度统计的过程基本就没了,没错,就是那么简简单单的几行,完整代码见https://github.com/Zephery/baidutongji/blob/master/baidu.py,但是,想要实现获取各种数据,仍需要做很多工作。
4.实际运用
(1)需要使用其他参数怎么办

python中提供了个可变参数来解决这一烦恼,详细请看http://www.jianshu.com/p/98f7e34845b5,可变参数允许你传入0个或任意个参数,这些可变参数在函数调用时自动组装为一个tuple,而关键字参数允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict。
def getresult(self, start_date, end_date, method, metrics, **kw):
base_url = "https://api.baidu.com/json/tongji/v1/ReportService/getData"
body = {"header": {"account_type": 1, "password": self.password, "token": self.token,
"username": self.username},
"body": {"siteId": self.siteId, "method": method, "start_date": start_date,
"end_date": end_date, "metrics": metrics}}
for key in kw: #对可变参数进行遍历,如果有的话就往body中加入
body['body'][key] = kw[key]使用方式:
result = self.getresult(start, end, "source/all/a",
"pv_count,visitor_count,avg_visit_time", viewType='visitor') #其中viewTYpe便是可变参数(2)获取的数据如何解析 百度统计返回的结果比较简洁而又反人类,以获取概览中的pv_count,visitor_count,ip_count,bounce_ratio,avg_visit_time为例子:
result = bd.getresult(start, end, "overview/getTimeTrendRpt",
"pv_count,visitor_count,ip_count,bounce_ratio,avg_visit_time")返回的结果是:
[[['2017/09/12'], ['2017/09/13'], ['2017/09/14'], ['2017/09/15'], ['2017/09/16'], ['2017/09/17'], ['2017/09/18']],
[[422, 76, 76, 41.94, 221],
[284, 67, 65, 50.63, 215],
[67, 23, 22, 52.17, 153],
[104, 13, 13, 36.36, 243],
[13, 4, 4, 33.33, 66],
[73, 7, 6, 37.5, 652],
[63, 11, 11, 33.33, 385]
], [], []]即:翻译成人话就是:
[[[date1,date2,...]],
[[date1的pv_count, date1的visitor_count, date1的ip_count, date1的bounce_ratio, date1的avg_visit_time],
[date2的pv_count, date2的visitor_count, date2的ip_count, date2的bounce_ratio, date2的avg_visit_time],
...,[]
],[],[]]极其反人类的设计。还好用的python,python数组的特性实在太强了。出了可以运用[x for x in range]这类语法之外,还能与三元符(x if y else x+1,如果y成立,那么结果是x,如果y不成立,那么结果是x+1)一起使用,这里注意:如果当天访问量为0,其返回的json结果是'--',所以要判断是不是为'--',归0化,才能在折线图等各种图上显示。下面是pv_count的例子:
pv_count = [x[0] if x[0] != '--' else 0 for x in result[1]](3)每周限制2000次 在开通数据导出服务的时候,不知道大家有没有注意到它的说明,即我们是不能实时监控的,只能将它放在临时数据库中,这里我们选择了Redis,并在centos里定义一个定时任务,每天全部更新一次即可。

python中redis的使用方法很简单,连接跟mysql类似:
# 字符串
pool = redis.ConnectionPool(host='your host ip', port=port, password='your auth') # TODO redis地址
r = redis.Redis(connection_pool=pool)本网站使用redis的数据结构只有set,方法也很简单,就是定义一个key,然后value是数组的字符串获取json。
ip_count = [x[2] if x[2] != '--' else 0 for x in result[1]]
r.set("ip_count", ip_count)
# json
name = [item[0]['name'] for item in data[0]]
count = 0
tojson = []
for item in data[1]:
temp = {}
temp["name"] = name[count]
temp["pv_count"] = item[0]
temp["visitor_count"] = item[1]
temp["average_stay_time"] = item[2]
tojson.append(temp)
count = count + 1
r.set("rukouyemian", json.dumps(tojson[:5]))5.基本代码
下面是基本的使用代码,完整的使用代码就不贴了,有兴趣可以去我的github上看看,完整代码,希望能给个star哈哈哈,感谢
import json
import time
import datetime
import urllib.parse
import urllib.request
base_url = "https://api.baidu.com/json/tongji/v1/ReportService/getData"
class Baidu(object):
def __init__(self, siteId, username, password, token):
self.siteId = siteId
self.username = username
self.password = password
self.token = token
def getresult(self, start_date, end_date, method, metrics, **kw):
base_url = "https://api.baidu.com/json/tongji/v1/ReportService/getData"
body = {"header": {"account_type": 1, "password": self.password, "token": self.token,
"username": self.username},
"body": {"siteId": self.siteId, "method": method, "start_date": start_date,
"end_date": end_date, "metrics": metrics}}
for key in kw:
body['body'][key] = kw[key]
data = bytes(json.dumps(body), 'utf8')
req = urllib.request.Request(base_url, data)
response = urllib.request.urlopen(req)
the_page = response.read()
return the_page.decode("utf-8")
if __name__ == '__main__':
# 日期开始
today = datetime.date.today()
yesterday = today - datetime.timedelta(days=1)
fifteenago = today - datetime.timedelta(days=7)
end, start = str(yesterday).replace("-", ""), str(fifteenago).replace("-", "")
# 日期结束
bd = Baidu(yoursiteid, "username", "password", "token")
result = bd.getresult(start, end, "overview/getTimeTrendRpt",
"pv_count,visitor_count,ip_count,bounce_ratio,avg_visit_time")
result = json.loads(result)
base = result["body"]["data"][0]["result"]["items"]
print(base)6.展示数据
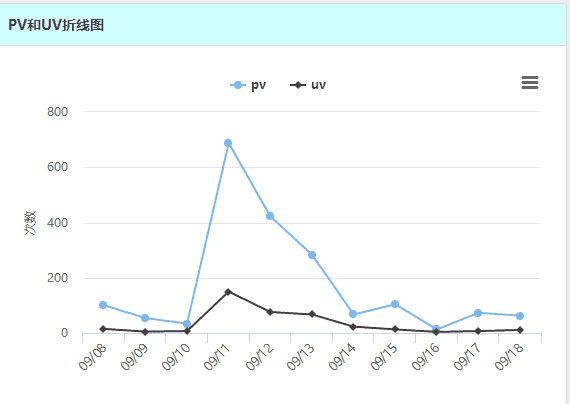
在将数据存进redis中之后,我们需要在博客中使用这些数据来制作图表。在newblog中使用方式也很简单,大概就是使用jedis读取数据,然后使用echarts或者highcharts展示。其中折线图以及线型图我都使用了highcharts,确实比echarts好看的多,但是地域图还是选择了echarts,毕竟中国的产品还是对中国的支持较好。 (1)PV、UV折线图 以图表PV、UV为例,由于存储进redis的是一个数组,所以,可以直接从redis中读取然后放到一个attribute里即可:
String pv_count = jedis.get("pv_count");
String visitor_count = jedis.get("visitor_count");
mv.addObject("pv_count", pv_count);
mv.addObject("visitor_count", visitor_count);jsp中的使用如下:
<div class="panel-heading" style="background-color: rgba(187,255,255,0.7)">
<div class="card-title">
<strong>PV和UV折线图</strong>
<div class="panel-body">
<div id="linecontainer" style="width: auto;height: 330px">
<script>
var chart = new Highcharts.Chart('linecontainer', {
title: {
text: null
},
credits: {
enabled: false
},
xAxis: {
categories: ${daterange}
},
yAxis: {
title: {
text: '次数'
},
plotLines: [{
value: 0,
width: 1,
color: '#808080'
}]
},
tooltip: {
valueSuffix: '次'
},
legend: {
borderWidth: 0,
align: "center", //程度标的目标地位
verticalAlign: "top", //垂直标的目标地位
x: 0, //间隔x轴的间隔
y: 0 //间隔Y轴的间隔
},
series: [{
name: 'pv',
data:${pv_count}
}, {
name: 'uv',
data:${visitor_count}
}]
})
</script>效果如下:
(2)地域访问量 在python代码中先获取地域的数据,其结果如下,百度统计跟echarts都是百度的,果然,自家人对自己人的支持真是特别友好的。
[{'pv_count': 649, 'pv_ratio': 7, 'visitor_count': 2684, 'name': '广东'}, {'pv_count': 2, 'pv_ratio': 2, 'visitor_count': 76, 'name': '四川'}, {'pv_count': 1, 'pv_ratio': 1, 'visitor_count': 3, 'name': '江苏'}]地域图目前支持最好的还是百度的echarts,使用方法见echarts的官网吧,这里不再阐述,展示地域图的时候需要获取下载两个文件,china.js(其提供了js和json,这里使用的js),echarts.js。 部分代码:
<script type="text/javascript">
var myChart = echarts.init(document.getElementById('diyu'));
option = {
tooltip: {
trigger: 'item'
},
legend: {
orient: 'vertical',
left: 'left'
},
visualMap: {
min: 0,
max:${diyumax},
left: 'left',
top: 'bottom',
text: ['高', '低'], // 文本,默认为数值文本
calculable: true
},
toolbox: {
show: true,
orient: 'vertical',
left: 'right',
top: 'center',
feature: {
dataView: {readOnly: false},
restore: {},
saveAsImage: {}
}
},
series: [
{
name: '访问量',
type: 'map',
mapType: 'china',
roam: false,
label: {
normal: {
show: true
},
emphasis: {
show: true
}
},
data: [
<c:forEach var="diyu" items="${diyu}">
{name: '${diyu.name}', value: ${to.pv_count}},
</c:forEach>
]
}
]
};
myChart.setOption(option);
</script>结果如下: 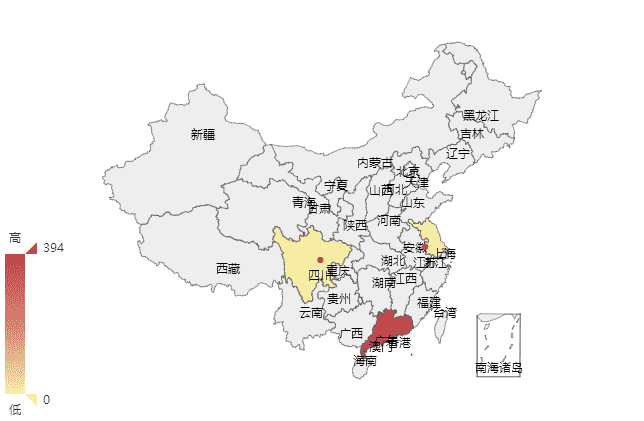
结语
网上关于日志系统的几乎都是ELK,对于小网站的,隐私不是很重要的还是可以用用百度统计的,这套系统也折磨了我挺久的,特别是它那反人类的返回数据。期初本来是想使用百度统计的,后来考虑了一下ELK,尝试之后发现,服务器配置跑不起来,还是安安稳稳的使用了百度统计,于此做成了这个系统,美观度还是不高,颜色需要优化一下。最后,希望能在GitHub上给我个star吧。
日志系统地址:http://www.wenzhihuai.com/log.html
个人网站网址:http://www.wenzhihuai.com
个人网站代码地址:https://github.com/Zephery/newblog
百度统计python代码地址:https://github.com/Zephery/baidutongji
万分感谢